
티스토리 뷰
QLoRA: Efficient Finetuning of Quantized LLMs - Abstract, Background
jhin.lee 2024. 6. 14. 17:19QLoRA는 2023년 5월 발표된 "QLoRA: Efficient Finetuning of Quantized LLMs"에서 등장한 용어다. (논문 링크)
2023년부터 시작해서 회사에서 AI 기술의 서비스 도입등을 검토하는 프로젝트에 참여하게 되었다.
해당 프로젝트에 참여하면서 로컬 장비로 LLM을 파인튜닝 하는 일을 해 볼 수 있었는데, 그 과정에서 4bit양자화의 도움을 많이 받았다.
어떤 기술인지 이해도 못하고 무작정 사용하는게 맘에 걸려서 따로 공부를 좀 진행하였다.
이 글에서는 해당 논문 3챕터 까지의 기술적인 내용에 대한 번역 및 해석,
그리고 논문에서 설명되지 않은 배경 기술에 대한 해설을 다루려고 한다.
Abstract (초록)
We present QLORA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance.
우리는 full 16-bit finetuning의 성능은 유지하면서 단일 48GB GPU에서 매개변수 모델을 미세 조정할 수 있을 만큼 메모리 사용량을 줄이는 효율적인 미세 조정 접근 방식인 QLoRA를 제시합니다.
해당 논문에서는 65B의 모델을 48GB 싱글 GPU로 파인튜닝 하는 것에 성공했다.
기계학습에서 모델 크기 뒤의 B는 10억개의 파라미터(또는 가중치)를 의미한다.
일반적으로 65B의 모델을 사용하려면, 파라미터의 자료형이 FP32(32-bit Floating Point)의 경우 VRAM 260GB+α 가 필요하다. (650억개 파라미터 * 32bit = 260GB)
이 논문에서는 이 모델을 48GB 싱글 GPU로 파인튜닝에 성공 했으므로 기존보다 상당히 적은 메모리를 사용하여 학습에 성공했다는 사실을 알 수 있다.
QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters (LoRA).
QLoRA는 고정된 4비트 양자화된 사전 학습 언어 모델을 통해 기울기를 LoRA(Low Rank Adapter)로 역전파합니다.
QLoRA introduces a number of innovations to save memory without sacrificing performance:
QLoRA는 성능 저하 없이 메모리를 절약할 수 있는 다양한 혁신 기술을 도입했습니다.
(a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights
(a) 4비트 NormalFloat(NF4), 정규 분포 가중치에 이론적으로 최적인 정보인 새로운 데이터 유형
(b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants
(b) 양자화 상수를 양자화하여 평균 메모리 공간을 줄이기 위한 이중 양자화
(c) Paged Optimizers to manage memory spikes.
(c) 메모리 급증을 관리하는 페이징 최적화 프로그램.
QLoRA주된 기술 개념은 4bit 양자화된 사전 학습 모델을 LoRA로 학습시키기 이다.
LoRA에 대한 개념은 논문의 Background 파트에서 다루고
논문의 핵심 개념인 4bit 양자화의 구체적인 기술은 아래 3가지다
a) NF4 데이터 타입을 사용
b) 이중 양자화 사용
c) 페이징 최적화 프로그램
Background
Background 파트는 3가지 소주제로 구성되어 있다.
- Block-wise k-bit Quantization
- Low-rank Adapters (LoRA)
- Memory Requirement of Parameter-Efficient Finetuning
Quantization
Quantization is the process of discretizing an input from a representation that holds more information to a representation with less information.
양자화는 더 많은 정보를 보유한 표현에서 더 적은 정보를 가진 표현으로 입력을 이산화하는 프로세스입니다.
It often means taking a data type with more bits and converting it to fewer bits, for example from 32-bit floats to 8-bit Integers.
이는 종종 더 많은 비트의 데이터 유형을 가져와 더 적은 비트로 변환하는 것을 의미합니다(예: 32비트 부동 소수점에서 8비트 정수로).
논문에 설명된 대로, 양자화는 더 많은 정보를 보유한 표현에서 더 적은 정보를 가진 표현으로 입력을 이산화하는 과정을 표현하는 일반적인 용어이다.
LLM의 트랜드는 모델의 크기가 커지는 방향으로 진행되었었다.
PaLM 540B, BLOOM 176B와 같이 대규모 LLM이 등장하였으며 크기가 큰 모델들을 학습 시키거나 *Inference하기 위해서는 엄청난 컴퓨팅 파워 (특히나 GPU)가 필요하게 되었다.
(*Inference (추론) - 이미 학습된 모델을 실제로 새로운 입력 데이터에 적용하여 결과를 내놓는 것, 원어 그대로 많이 사용)
이를 해결하기 위한 다양한 방안들이 제시되었고, 양자화도 그 중 하나이다.
논문에서는 FP32(32-bit Floating Point) 자료형을 [−127, 127] 범위의 int8로 양자화하고 다시 역양자화 하는 예시를 보여준다.
To ensure that the entire range of the low-bit data type is used, the input data type is commonly rescaled into the target data type range through normalization by the absolute maximum of the input elements, which are usually structured as a tensor
낮은 비트 데이터 유형의 전체 범위가 사용되도록 하기 위해 입력 데이터 유형은 일반적으로 텐서로 구조화되는 입력 요소의 절대 최대값에 의한 정규화를 통해 대상 데이터 유형 범위로 재조정됩니다.
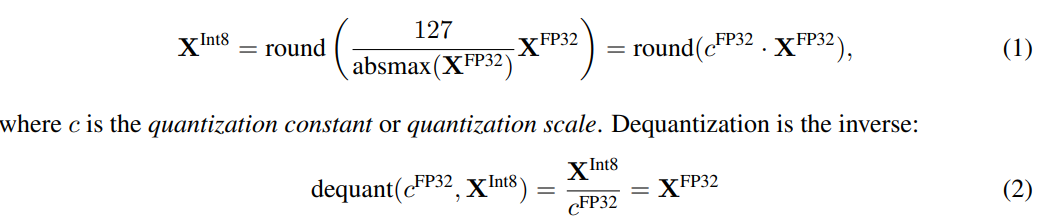
수식이라 골아프지만 차분히 읽어보면 어려운 개념은 아니다.
Int8의 최대범위인 127을 주어진 FP32데이터중 절대값이 가장 큰 값으로 나누고 (양자화 인자 c로 표현됨) 그것을 원본 데이터에 곱하여 양자화한다. 그리고 정수형으로 반올림 하여 양자화를 완료한다.
반대는 양자화된 데이터를 양자화 인자로 나누어 역양자화를 진행한다.
The problem with this approach is that if a large magnitude value (i.e., an outlier) occurs in the input tensor, then the quantization bins—certain bit combinations—are not utilized well with few or no numbers quantized in some bins.
이 접근 방식의 문제점은 입력 텐서에서 큰 크기 값(이상치)이 발생하면 일부 빈(특정 비트 조합)에서 양자화된 숫자가 거의 또는 전혀 없어서 양자화 빈이 잘 활용되지 않는다는 것입니다.
만약 양자화 대상 데이터가 대체로 1~10 사이에 분포해 있는데, 최대값이 1000이라고 가정 해보자
양자화가 완료되면 1000을 제외한 나머지 값들은 대부분 0으로 양자화 될 것이다.
즉, 이상치 1개로 인해 양자화 시 대부분의 정보가 유실되게 된다.
To prevent the outlier issue, a common approach is to chunk the input tensor into blocks that are independently quantized, each with their own quantization constant c.
이상치 문제를 방지하기 위한 일반적인 접근 방식은 입력 텐서를 독립적으로 양자화되는 블록으로 청크하는 것입니다. 각 블록은 자체 양자화 상수 c를 갖습니다.
Block-wise k-bit Quantization이란, 양자화에서 이상치 문제를 방지하기 위해서 입력 텐서를 분할하여 각각의 블록을 독립적으로 k-bit로 양자화 하는것을 말한다.
Low-rank Adapters (LoRA)
LoRA는 MS가 2021년에 발표한 "LoRA: Low-Rank Adaptation of Large Language Models" 라는 논문에서 발표된 개념이다.

Low-rank Adapter (LoRA) finetuning is a method that reduces memory requirements by using a small set of trainable parameters, often termed adapters, while not updating the full model parameters which remain fixed.
LoRA(낮은 순위 어댑터) 미세 조정은 어댑터라고 불리는 훈련 가능한 작은 매개변수 집합을 사용하여 메모리 요구 사항을 줄이는 동시에 고정된 전체 모델의 매개변수를 업데이트하지 않는 방법입니다.
LoRA는 기반 모델의 매개변수는 고정하고, 어댑터라고 부르는 훈련 가능한 작은 매개변수 집합을 사용하여 메모리 요구 사항을 줄이는 파인튜닝 방법론이다.
LoRA에 대해서는 일단 구체적인 기술적 설명은 적지 않고 개념만 이해하고 넘어가도록 하겠다.
Memory Requirement of Parameter-Efficient Finetuning (PEFT 방법론에서의 메모리 요구 사항)
PEFT(Parameter Efficient Finetuning)라는 용어가 정확히 언제부터 널리 쓰인 것인지.. 출처를 조사했지만 알 수 없었다.
다만 PEFT는 파인튜닝에서, 대부분의 매개변수를 동결하면서 소수의 매개변수만 미세 조정 하는 방법론이다.
LoRA와 비슷한 설명이라고 느낄 수 있는데, LoRA가 대표적인 PEFT 방법 중 하나 이다.
LoRA의 인지도가 높다 보니 LoRA와 용어 자체가 혼용 되어서 사용 되기도 하는 것 같고, hugging face의 라이브러리인 PEFT자체를 지칭하는 말로 쓰이기도 한다.
One important point of discussion is the memory requirement of LoRA during training both in terms of the number and size of adapters used.
LoRA에서 한 가지 중요한 점 중 하나는, LoRA 훈련 중 사용되는 어댑터의 수와 크기 측면에서의 메모리 요구 사항입니다.
Since the memory footprint of LoRA is so minimal, we can use more adapters to improve performance without significantly increasing the total memory used.
LoRA의 메모리 공간은 매우 작기 때문에 사용된 총 메모리를 크게 늘리지 않고도 더 많은 어댑터를 사용하여 성능을 향상 시킬 수 있습니다.
Parameter Efficient Finetuning (PEFT) method, most of the memory footprint for LLM finetuning comes from activation gradients and not from the learned LoRA parameters.
PEFT 방법론에서, LLM 파인튜닝을 위해 사용되는 대부분의 메모리는 학습된 LoRA 매개변수가 아닌 활성화 기울기에서 비롯됩니다.
여기에서 활성화 기울기에서 비롯됩니다 라고 번역한 부분은 정확한 번역이 어려워서 일단 써두었고. 밑에 gradient checkpointing의 설명을 보고 이해하시면 되겠다.
With gradient checkpointing, the input gradients reduce to an average of 18 MB per sequence making them more memory intensive than all LoRA weights combined.
gradient checkpointing을 사용하면 입력 기울기가 시퀀스당 평균 18MB로 줄어들어 모든 LoRA 가중치를 합친 것보다 메모리 집약도가 높아집니다.
In comparison, the 4-bit base model consumes 5,048 MB of memory.
이에 비해 4비트 기본 모델은 5,048MB의 메모리를 소비합니다.
This highlights that gradient checkpointing is important but also that aggressively reducing the amount of LoRA parameter yields only minor memory benefits.
이는 gradient checkpointing이 중요하지만 LoRA 매개변수의 양을 적극적으로 줄이면 메모리 이점이 미미하다는 점을 강조합니다.
As discussed later, this is crucial for recovering full 16-bit precision performance. 나중에 설명하겠지만 이는 완전한 16비트 정밀도 성능을 복구하는 데 중요합니다.
전하고 싶은 내용은 QLoRA에서는 4비트 양자화를 하기 때문에 gradient checkpointing의 메모리 절약 이점이 미미하다는 점을 말한다.
gradient checkpointing란,
기존 역전파 과정에서는 빠른 계산을 위해 당장 사용하지 않는 노드의 값이더라도 저장 해 두는데,
이는 연산 속도 측면에서 장점이 있지만 그만큼 저장해야 할 가중치가 늘어나 메모리 사용량이 늘어난다는 단점이 있다.
'Study > AI, ML' 카테고리의 다른 글
| '하네스 엔지니어링' Open AI Blog 글 읽어보기 (0) | 2026.06.24 |
|---|---|
| [논문 리뷰] 추론 모델과 COT를 이해하면서, 애플의 The Illusion of Thinking 논문 초록 읽기 (3) | 2025.06.19 |
| OpenAI, LLM, ChatGPT (0) | 2024.06.12 |